





카카오, ‘카나나-2’ 업데이트 모델 4종 오픈소스 공개…고효율 에이전트 AI 경쟁력 강화
MoE 아키텍처 적용으로 범용 GPU에서도 구동…수천억 파라미터 차세대 모델 개발도 속도



![]() 황수오⁄ 2026.01.20 11:00:04
황수오⁄ 2026.01.20 11:00:04
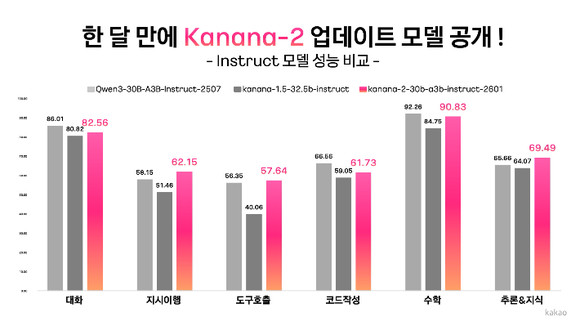
카카오가 자체 개발한 차세대 언어모델 ‘Kanana-2(카나나-2)’를 업데이트하고, 성능을 대폭 개선한 4종의 모델을 오픈소스로 추가 공개했다.
카카오는 20일 ‘Kanana-2’ 업데이트 모델 4종을 허깅페이스를 통해 공개했다고 밝혔다. 카나나-2는 지난해 12월 처음 오픈소스로 선보인 언어모델로, 카카오는 한 달여 만에 효율과 성능을 동시에 끌어올린 개량 모델을 내놓았다.
이번에 공개된 모델의 핵심은 ‘전문가 혼합(MoE, Mixture of Experts)’ 아키텍처다. 전체 파라미터는 320억 개 규모지만, 실제 추론 과정에서는 약 30억 개의 파라미터만 선택적으로 활성화해 연산 효율을 높였다. 이를 통해 엔비디아 A100 수준의 범용 GPU에서도 원활하게 구동되도록 최적화했다. 최신 초고가 인프라 없이도 고성능 AI 활용이 가능해 중소기업과 연구자들의 접근성을 높였다는 설명이다.
카카오는 MoE 학습에 필요한 핵심 커널을 직접 개발해 학습 속도를 높이고 메모리 사용량을 줄였다. 여기에 사전 학습과 사후 학습 사이에 ‘미드 트레이닝’ 단계를 새로 도입하고, 기존 지식을 잊는 현상을 방지하기 위한 ‘리플레이’ 기법을 적용해 성능 안정성도 확보했다.
이번에 공개된 모델은 기본(Base), 지시 이행(Instruct), 추론 특화(Thinking), 미드 트레이닝(Mid-training) 등 4종이다. 특히 연구 활용도가 높은 미드 트레이닝용 기본 모델까지 함께 공개해 오픈소스 생태계 기여도를 높였다.
카카오는 이번 업데이트를 통해 에이전트 AI 구현 역량도 강화했다고 강조했다. 멀티턴 도구 호출 데이터를 집중 학습시켜 복잡한 지시를 이해하고 적절한 도구를 선택·호출하는 능력을 개선했다. 내부 평가에서는 동급 경쟁 모델 대비 지시 이행 정확도와 한국어 성능 등에서 우위를 보였다는 설명이다.
김병학 카카오 카나나 성과리더는 “보편적인 인프라 환경에서도 실용적인 에이전트 AI를 구현할 수 있도록 고효율 모델을 공개했다”며 “국내 AI 연구와 기업의 AI 도입에 새로운 선택지가 되길 기대한다”고 말했다.
한편 카카오는 MoE 구조 기반의 수천억 파라미터 모델 ‘Kanana-2-155b-a17b’도 학습 중이다. 해당 모델은 글로벌 경쟁 모델과 비교해 적은 데이터로도 유사한 성능을 기록했으며, 한국어 질의 응답과 수학 영역에서는 우수한 결과를 보였다는 설명이다. 카카오는 향후 글로벌 최상위 수준의 파운데이션 모델 개발을 이어갈 계획이다.
<문화경제 황수오 기자>
- 관련태그
- 카카오 Kanana-2 카나나-2 MoE 아키텍처 오픈소스 AI 모델
주요 기사











많이 읽은 기사















(03781) 서울시 서대문구 연희로 52-20 CNB빌딩 TEL:02-396-3733 FAX:02-396-7330
정기간행물 등록번호:서울다07522(등록일:2006.10.24), 인터넷신문등록번호:서울아04864(등록일:2017.12.06)
문화경제 발행인/편집인: 주금옥, 편집국장: 정의식, 청소년보호책임자: 류창림
대표메일 : cnbnews@cnbnews.com [이메일주소 무단수집 거부]